


Recruiters want to see more than programming skills and a biology degree. They’re looking for someone who can bring real analytical value to their team – someone who can bridge the gap between biology and big data.
This guide will walk you through how to turn your research, coding experience, and scientific background into a compelling CV. With a Bioinformatics CV example and expert advice, you’ll have everything you need to secure your next academic or industry role.
Bioinformatics CV sample

How to write your Bioinformatics CV
Discover how to craft a winning Bioinformatics CV that lands interviews with this simple step-by-step guide.
Writing code to process genomic data? Sure. Visualising protein networks across species? No problem. Writing a CV that captures all of that in two pages or less? Slightly less intuitive.
This guide will help you craft your bioinformatics CV with clarity, and – just as importantly – tailor your experience and skills to reflect the demands of hiring managers across research and healthcare settings.
How to structure and format your Bioinformatics CV
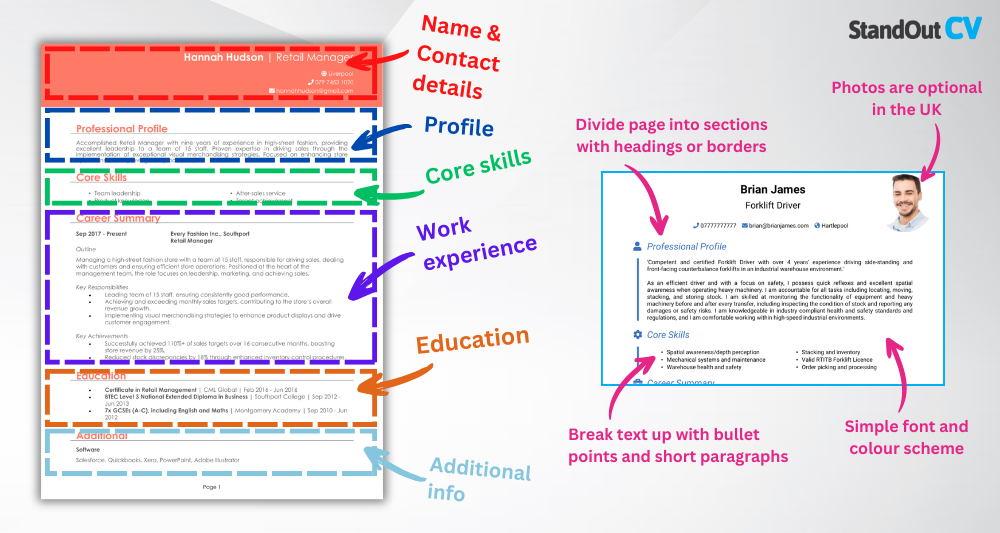

Bioinformatics sits at the intersection of biology and statistics – and your CV should reflect that same clarity and structure. A well-organised layout makes it easy for recruiters to scan through your academic qualifications and project experience without confusion and mistakes.
Here’s the layout to follow:
- Name and contact details – Start with your name and personal details – make it simple for recruiters to reach you. Including a photo is a personal choice.
- Profile – Use this section to summarise your experience, strengths, and what makes you a standout candidate.
- Core skills – Outline your primary competencies to give recruiters a snapshot of your strengths.
- Work experience – Walk through your professional experience, beginning with your latest position and moving backwards.
- Education – Outline your education and certifications, focusing on those most relevant to the role.
- Additional info – This section is optional, but it’s a good place for hobbies and interests that complement your CV.
To keep your CV sharp and readable, use a clean, academic-appropriate font and break up the content with clear section headings and bullet points in each section. Stick to two pages length max, use white space strategically, and avoid unnecessary graphics or formatting. Treat your CV format like a well-documented script – straightforward and precise.
How to write a Bioinformatics CV profile


This section is your CV’s headline – a quick summary of why you’re the kind of bioinformatician who adds measurable value to research or development teams. It’s not just about where you studied or what you know, but what you bring to the table: technical depth, cross-disciplinary insight, and the ability to solve biological problems with code.
Recruiters want to understand how your work translates into real-world outcomes. So focus your CV profile on the benefit you’d bring to anyone who takes you on board.
Bioinformatics CV profile examples
Profile 1
Experienced Bioinformatics Specialist with over 10 years in genomics research and data analysis for academic and pharmaceutical institutions. Skilled in analysing large-scale sequencing data, developing custom pipelines, and integrating multi-omics datasets. Proficient in R, Python, and tools like GATK and Galaxy.
Profile 2
Analytical Bioinformatics Scientist with seven years of experience supporting translational research and clinical trials. Adept at designing data workflows, processing next-generation sequencing (NGS) data, and collaborating with biostatisticians and wet-lab teams. Strong background in oncology and immunogenomics research.
Profile 3
Detail-oriented Bioinformatician with five years of experience in computational biology and software development for life sciences research. Experienced in variant calling, data visualisation, and creating reproducible pipelines using Snakemake and Docker. Comfortable working in cross-disciplinary teams in both academic and biotech settings.


Details to put in your Bioinformatics CV profile
To show your value clearly, include:
- Where you worked – Academic research groups, pharma R&D teams, genomics labs, hospitals
- Top qualifications – MSc or PhD in Bioinformatics, Systems Biology, Computational Biology
- Key strengths – Large-scale data analysis, pipeline automation, statistical modelling
- Specialisms – Genomics, transcriptomics, metagenomics, structural bioinformatics, etc.
- Tools and outcomes – e.g. using Python to optimise RNA-seq workflows or helping translate results into actionable diagnostics
What to include in the core skills section of your CV


When recruiters scan your CV, they’re looking for clear evidence of technical ability. This section should focus on hard, tangible CV skills – tools, languages, and domain-specific expertise – not vague phrases.
Mention your proficiency with programming languages, and reference your understanding of statistical techniques, cloud computing for data handling, or experience in creating reproducible pipelines.
This short list is your best chance to align yourself with the job spec – so make sure your listed skills are targeted, recent, and immediately recognisable to employers in the bioinformatics space.
What are the most important skills for a Bioinformatics CV?
- Genomic Data Analysis – Processing and interpreting large-scale DNA and RNA sequencing data to identify genetic variations and patterns.
- Biological Database Management – Using and curating databases like NCBI, Ensembl, and UniProt to retrieve and manage biological data.
- Algorithm and Tool Development – Creating custom scripts and pipelines for data analysis using languages like Python, R, or Perl.
- Next-Generation Sequencing (NGS) Interpretation – Analysing NGS data for applications such as variant calling, gene expression, and genome assembly.
- Statistical Modelling and Data Visualisation – Applying statistical techniques to biological data and creating visual outputs to support interpretation.
- Workflow Automation and Pipeline Integration – Building reproducible and scalable analysis pipelines using tools like Snakemake or Nextflow.
- Comparative Genomics – Comparing genomes across species or populations to study evolution, gene function, or disease susceptibility.
- Functional Annotation and Pathway Analysis – Linking gene or protein sequences to biological functions, pathways, and phenotypes using bioinformatics tools.
- High-Performance Computing Utilisation – Leveraging cluster computing or cloud platforms for processing large-scale biological datasets.
- Interdisciplinary Collaboration – Working with biologists, clinicians, and data scientists to translate complex biological questions into computational solutions.
How to write a strong work experience section for your CV


This section proves that you can put your academic and technical knowledge into real-world practice. Whether your background is in academia, healthcare, or industry, employers want to see how you applied your skills and contributed to successful projects.
List your work experience in reverse chronological order. For each position, begin with a short overview of the lab, company, or research focus. Then use bullet points to outline what you did and what impact it had – for instance, achievements like improving the speed of a variant-calling pipeline or helping validate biomarkers in clinical datasets.
Don’t shy away from referencing collaboration: bioinformatics rarely happens in isolation, and your ability to work with biologists, data scientists, or clinicians matters.
The best way to structure job entries on your CV

- Outline – Briefly describe the lab, research group, or company, what kind of work it focused on, and your position in the team.
- Responsibilities – Use action words like “analysed” and “developed.” For example: “analysed RNA-seq data using custom R scripts and Bioconductor packages” or “developed automated pipelines for WGS data analysis using Snakemake.” Mention tools, methods, and data types where relevant.
- Achievements – Highlight your impact: reduced processing time, improved reproducibility, published results, or contributions to high-impact studies. Use data or outcomes if available.
Sample jobs for Bioinformatics
Bioinformatics Analyst | Genica Research Institute
Outline
Supported genomic and transcriptomic research projects for a leading academic centre, analysing large-scale sequencing data and developing custom pipelines for RNA-seq and DNA-seq datasets.
Responsibilities
- Processed raw NGS data using tools such as STAR, BWA, and DESeq2
- Developed R and Python scripts to automate data cleaning and analysis
- Collaborated with researchers to design experiments and interpret results
- Created interactive dashboards to visualise gene expression and variant data
- Maintained version control using Git and documented pipelines for reproducibility
Achievements
- Contributed to 4 peer-reviewed publications in genomics and transcriptomics
- Reduced pipeline runtime by 35% through workflow optimisation
- Supported grant-winning projects by delivering timely, interpretable results
Bioinformatics Scientist | Orion Therapeutics Ltd
Outline
Worked within the R&D team of a biotech company focused on immuno-oncology, supporting preclinical development through analysis of genomic and single-cell datasets.
Responsibilities
- Analysed single-cell RNA-seq and bulk RNA-seq datasets using Seurat and edgeR
- Integrated multi-omics data to identify therapeutic targets and biomarkers
- Provided data-driven insights to immunologists and clinical researchers
- Managed cloud computing environments (AWS) for large dataset processing
- Ensured pipeline compliance with data protection and regulatory standards
Achievements
- Helped identify two novel targets now advancing to early-stage development
- Reduced cloud compute costs by 20% through efficient resource allocation
- Presented findings at international oncology research symposium
Bioinformatician | Stratadata Solutions
Outline
Provided bioinformatics consulting services to pharmaceutical and healthcare clients, supporting personalised medicine initiatives and genomic data management.
Responsibilities
- Built analysis pipelines for WES and WGS datasets using Nextflow and GATK
- Delivered variant annotation and prioritisation reports for clinical genetics teams
- Standardised data processing protocols across multiple client projects
- Trained end users on pipeline usage and result interpretation
- Ensured secure handling and storage of sensitive genetic data
Achievements
- Enabled 3 client projects to meet regulatory data reporting deadlines
- Designed reusable pipeline templates that cut onboarding time by 50%
- Maintained 99.8% data accuracy across audited client submissions
How to list your educational history


Education is a major component of your CV in this field – especially if you’re working in research or applying to academic positions. Start with your most recent qualification, typically an MSc or PhD in a relevant subject, followed by your undergraduate degree.
Mention your degree discipline, institution, and (optionally) your dissertation or thesis focus if it’s directly relevant to the role. You can also reference specific modules or research placements if you’re early in your career.
What are the best qualifications for a Bioinformatics CV?
- MSc in Bioinformatics, Computational Biology, or Systems Biology – Core training for most roles in research or industry
- PhD in Bioinformatics or a relevant interdisciplinary field – Essential for academic or high-level analytical roles
- BSc in Biological Sciences with strong programming coursework – A good foundation for entry-level bioinformatics roles
- Certifications in Python for Data Science or R Programming – Helps demonstrate software competency to hiring managers
- Training in Linux command line, Git, or workflow tools – Highly valued for reproducible and collaborative research work
